Jag hade förmånen att få opponera på studenterna i Riskanalysmetoder och deras projektuppgift inom området ”säkerhet” i förra veckan. Uppgiften de fick var väldefinierad:
Avgör om en lagring av klorgas kan tillåtas på en industrifastighet i centrala Malmö
Med hjälp av beräkningar av individ-, medel- och samhällsrisk för tre bestämda scenarier skulle studenterna avgöra om lagring av klorgas kan tillåtas utifrån ett riskperspektiv. De tre scenarierna var:
- Tankens innehåll töms på 10 min (0,7×10-6 år-1)
- Tankutsläpp genom ett hål med diameter 10 mm. (1,1×10-5 år-1)
- Litet rörbrott (5 mm) (5×10-6 år-1m-1)
Resultatet skiljer kraftigt (!) mellan de olika grupperna. Jag har valt att redovisa spridningen med hjälp av några histogram. Den stora orsaken till spridningen är framförallt valet av stabilitetsklass och vindhastighet. De flesta grupper väljer att jobbar mycket konservativt med stabila atmosfärsförhållanden och låga vindhastigheter.
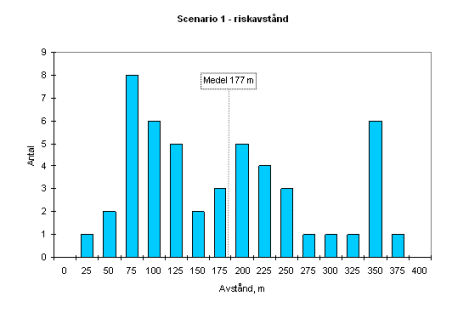
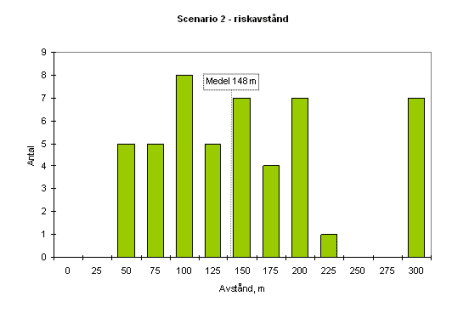
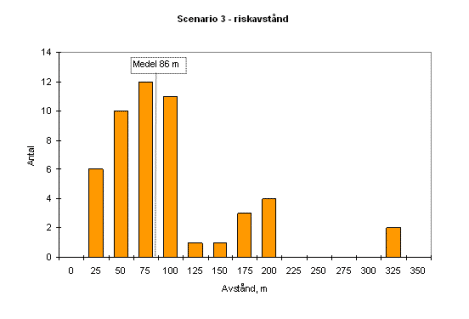 Â
Â
I kommande inlägg tänkte jag visa på spridningen i beräkningen av de olika riskmåtten.
Där e’ de =)
Fredrik, hade vart intressant att se hur du hade gjort och jämfört detta med de resultat som grupperna kom fram till.
Har resultaten frÃ¥n känslighetsanalyserna redovisats i histogrammen ovan? Annars förstÃ¥r jag nog inte ”antal” rätt.
Resultatet liknar det som Kurt Lauridsen diskuterar om i sin rapport om Ammoniak-anläggningen när det är flera olika personer som gör en riskanalys och resultaten är väldigt spridda. Hur kan det komma sig i vårt fall när vi i stort sett har alla uppgifter framför oss? BfK är inte heller det svåraste programmet att använda och antaganden borde i skilja så mycket?!
Hur såg de olika riskbedömningarna ut angående om det var OK med att införa klortanken? Intressant!
Om jag summerar antalet fall som de 16 grupperna har räknat pÃ¥ sÃ¥ blir det summan av ”antal” i figurerna ovan. Jag har inte tagit med känslighetsanalyserna, utan endast de beräkningar som gjorts med utgÃ¥ngspunkt av händelseträden. Vissa grupper gör endast en spridningsberäkning per scenario, medan nÃ¥gon extrem gör 12 (!). Snittet ligger kring 2-4 fall per scenario.
Bra reflektion angÃ¥ende ”Assurance-projektet” (http://www.risoe.dk/rispubl/SYS/syspdf/ris-r-1344.pdf). Om det är sÃ¥ här stor spridning i denna väldefinierande uppgift sÃ¥ är det lätt att inse hur stor spridningen kan vara med avseende pÃ¥ risker för en hel industri. Tyvärr har jag inte tid att gÃ¥ mer i detalj varför resultaten skiljer i huvudsak pga val av vindhastighet och stabilitetsklass.
Jag har faktiskt funderat på att göra en egen analys med de modeller som jag använder idag. Det hade varit kul att jämföra. Kanske får jag tid till det lite senare.